최소 신장 트리와 알고리즘
신장 트리(Spanning Tree)
신장 트리란 그래프 내의 모든 정점을 포함하는 트리이다. 신장 트리는 트리의 특수한 형태로써, 모든 정점이 연결되어 있어야 하고 사이클을 포함해서는 안된다. 따라서 신장 트리는 그래프에 있는 n개의 정점을 정확히 (n-1)개의 간선으로 연결하게 된다. 신장 트리는 그래프의 최소 연결 부분 그래프가 된다. 여기서 최소의 의미는 간선의 수가 가장 적다는 뜻이다. 하지만 한 그래프의 신장 트리에서 간선 간 비용을 붙일 경우, 신장 트리간의 비용은 같지 않다.
최소 신장 트리(MST:Minimum Spanning Tree)
최소 비용 신장 트리는 신장 트리 중에서 사용된 간선들의 가중치 합이 최소인 신장 트리를 말한다.
Kruskal의 MST 알고리즘
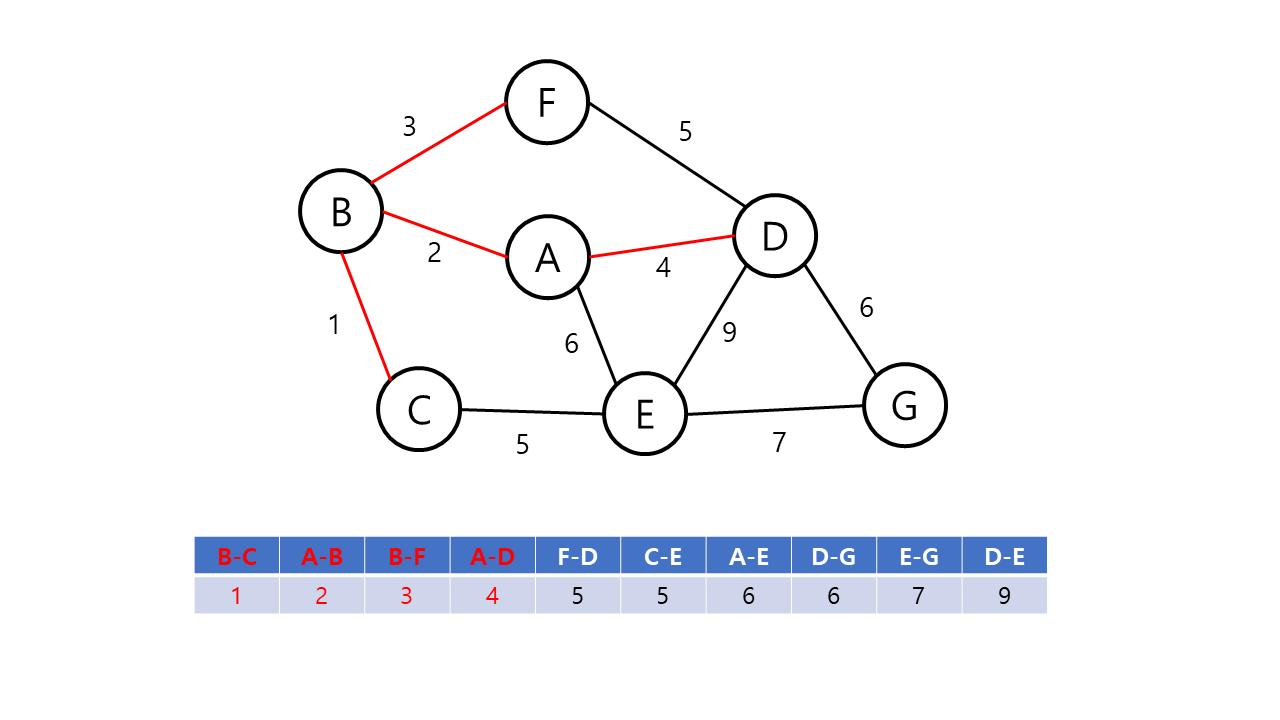
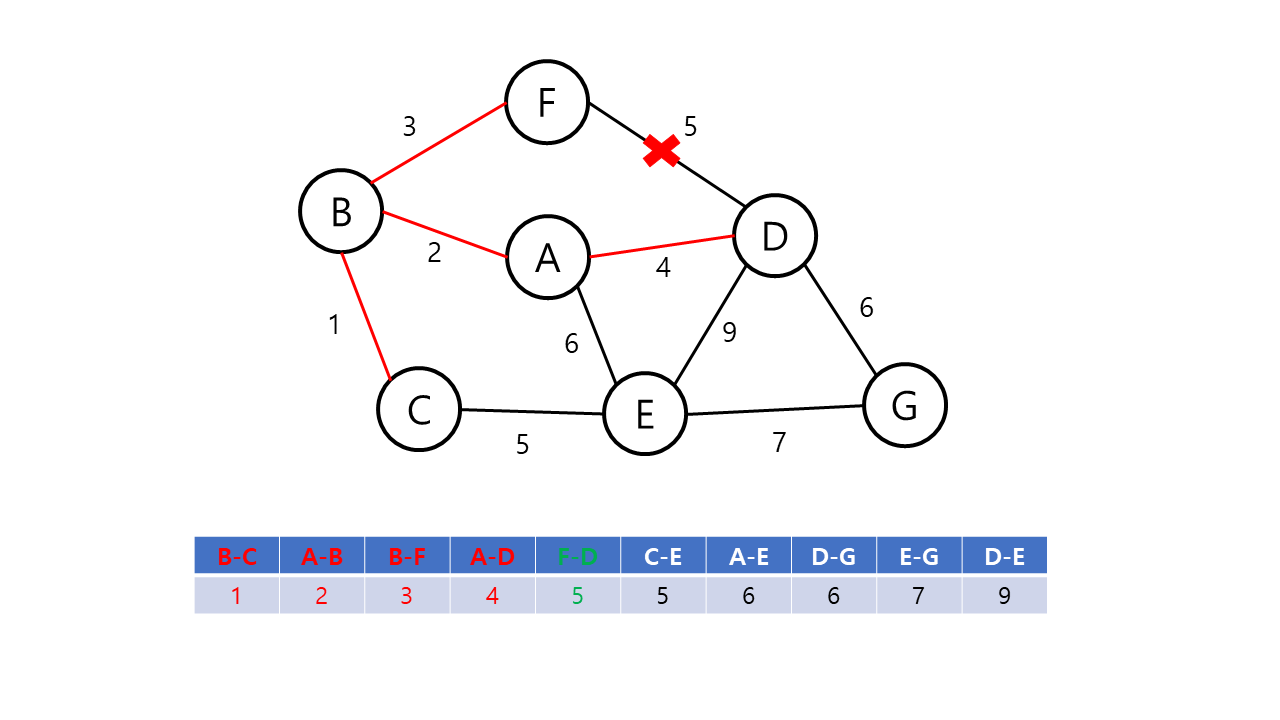
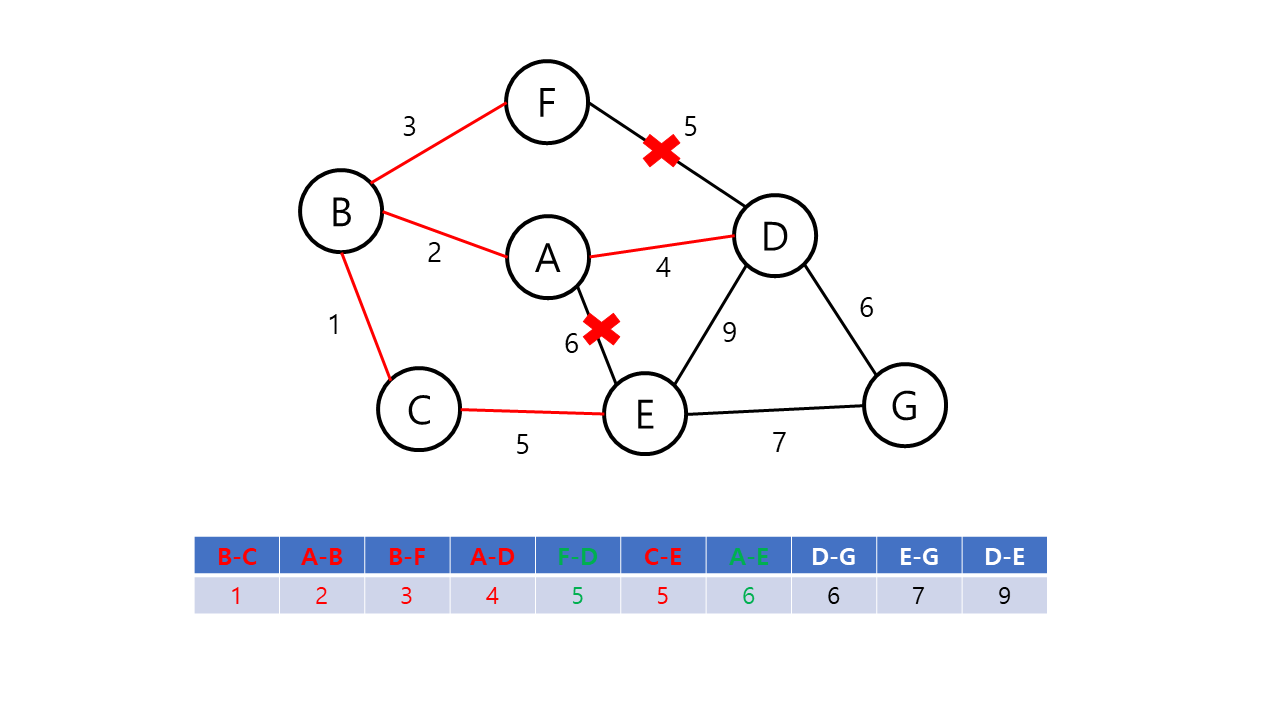
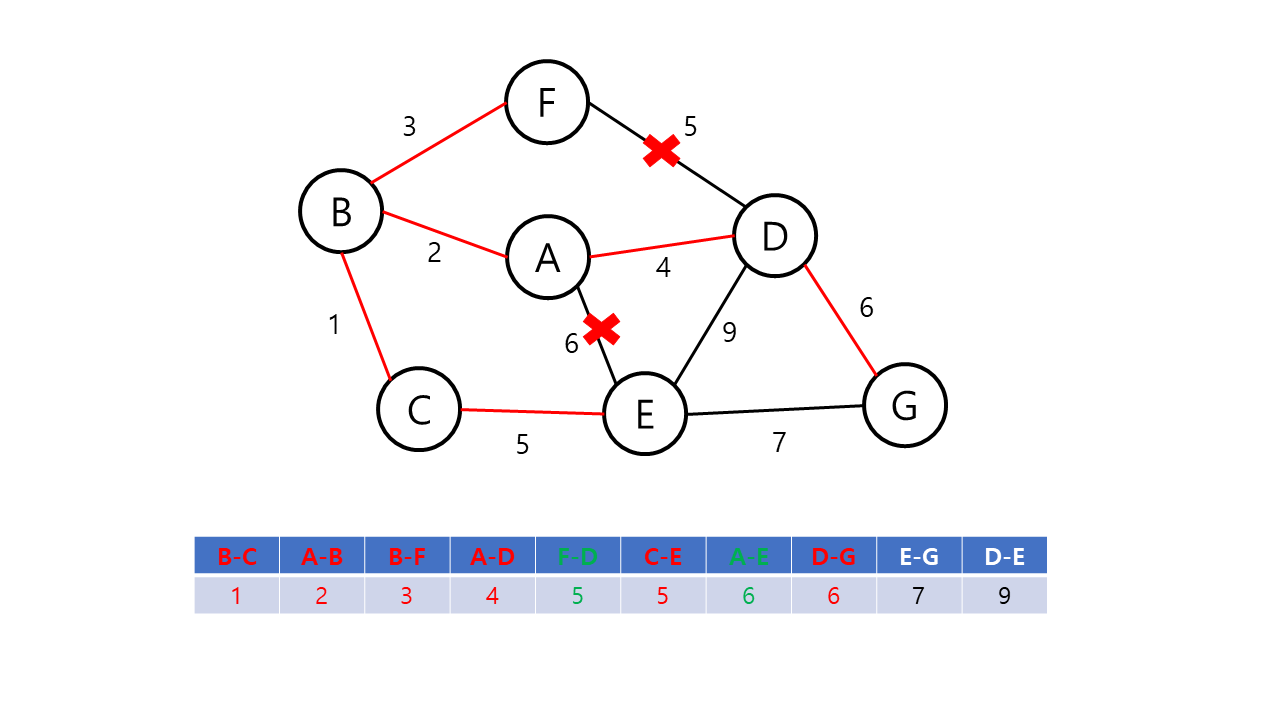
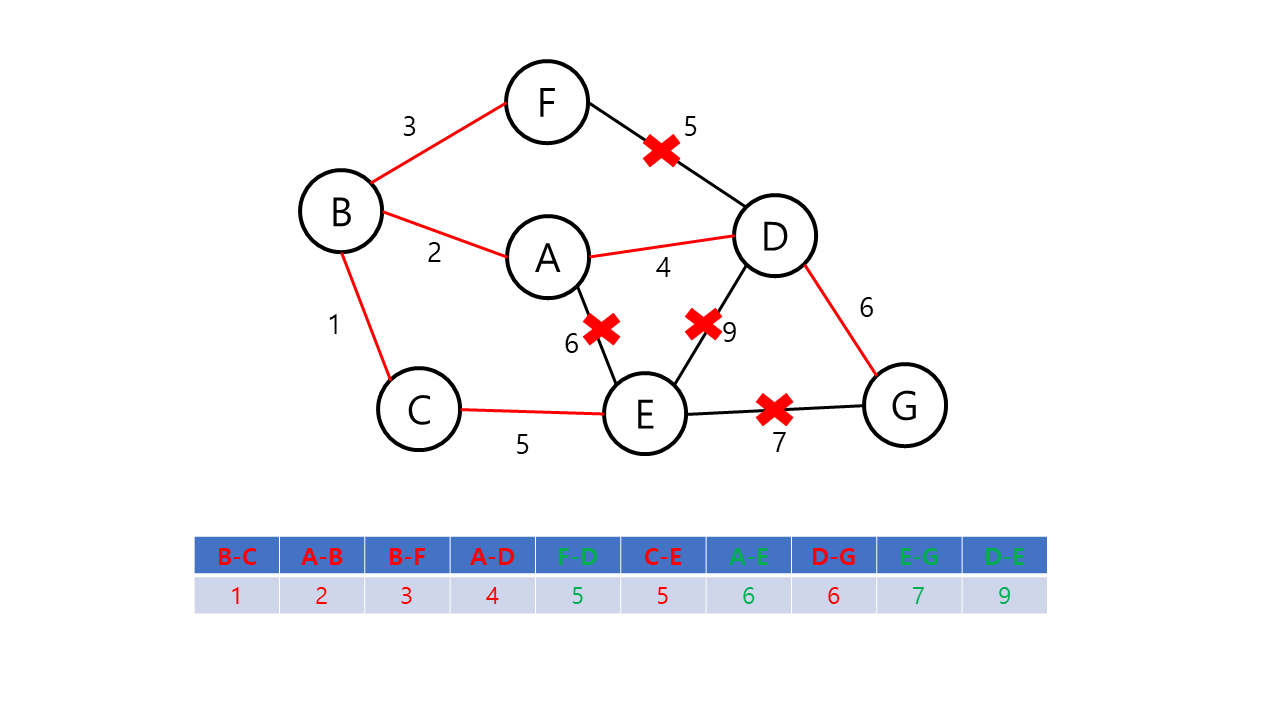
Kruskal의 알고리즘은 탐욕적인 방법(greedy method)을 이용한다. 탐욕적인 방법에서는 결정을 해야하는 순간마다 그 순간에 가장 좋다고 생각되는 해법을 선택함으로써 최종적인 해답에 도달하는 기법이다. 이 때, 순간의 해답은 최적이지만 최종적인 해답이 전체적인 관점에서 최적이라는 보장이 없으므로 탐욕적인 방법은 항상 최적의 해답인지를 검증해야 한다. Kruskal의 알고리즘은 최소 비용 신장 트리가 최소 비용의 간선으로 구성됨과 동시에 사이클을 포함하지 않는다는 조건에 근거하여, 각 단계에서 비용이 최소이면서 사이클이 만들어지지 않는 간선을 선택한다.
동작 방식
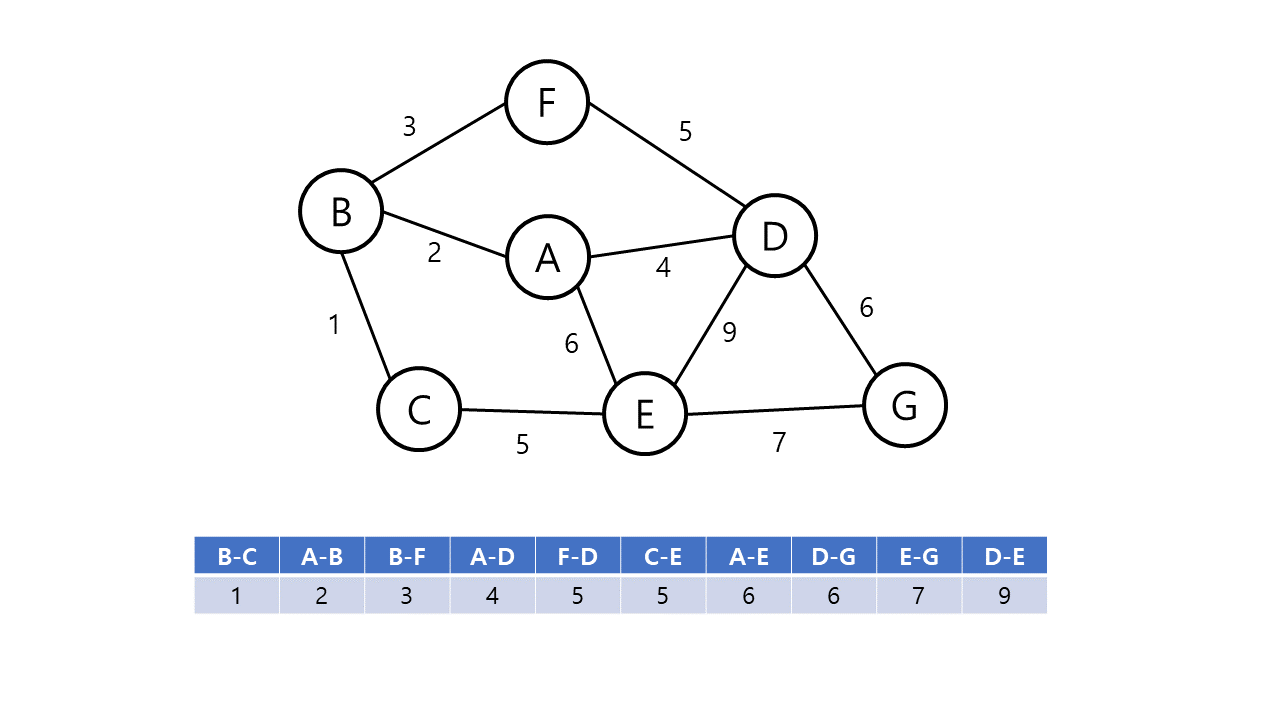
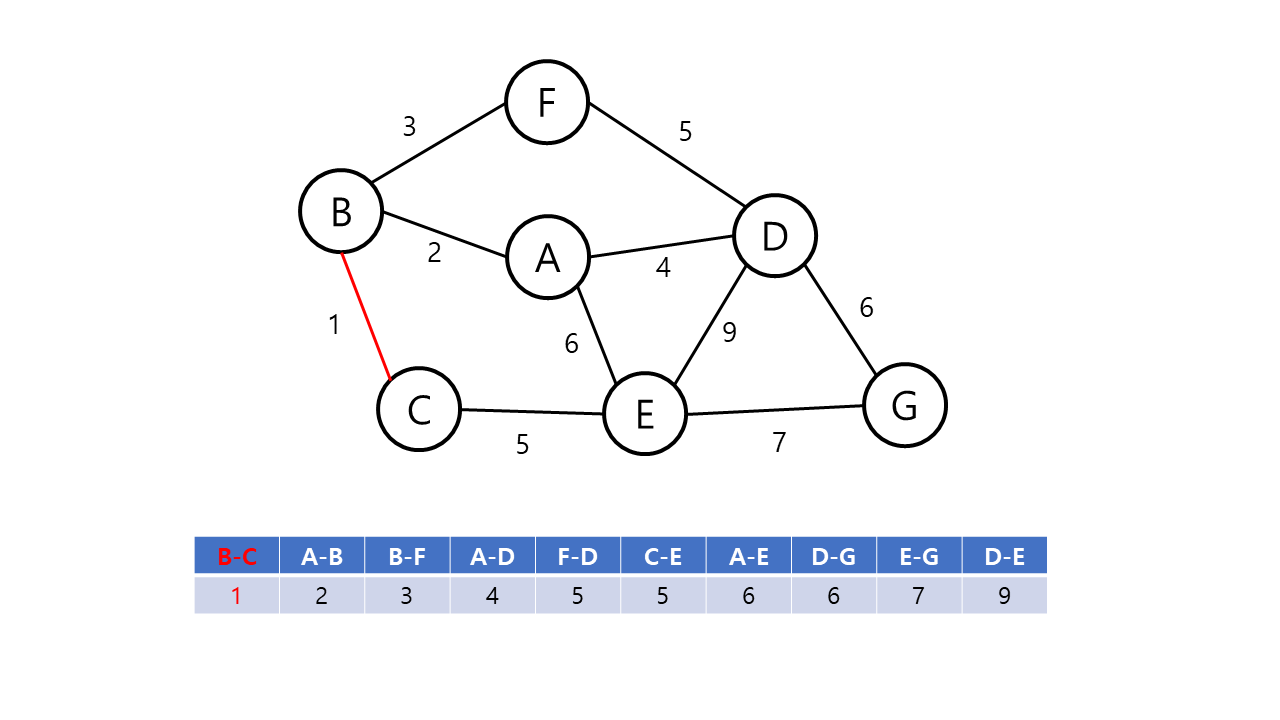
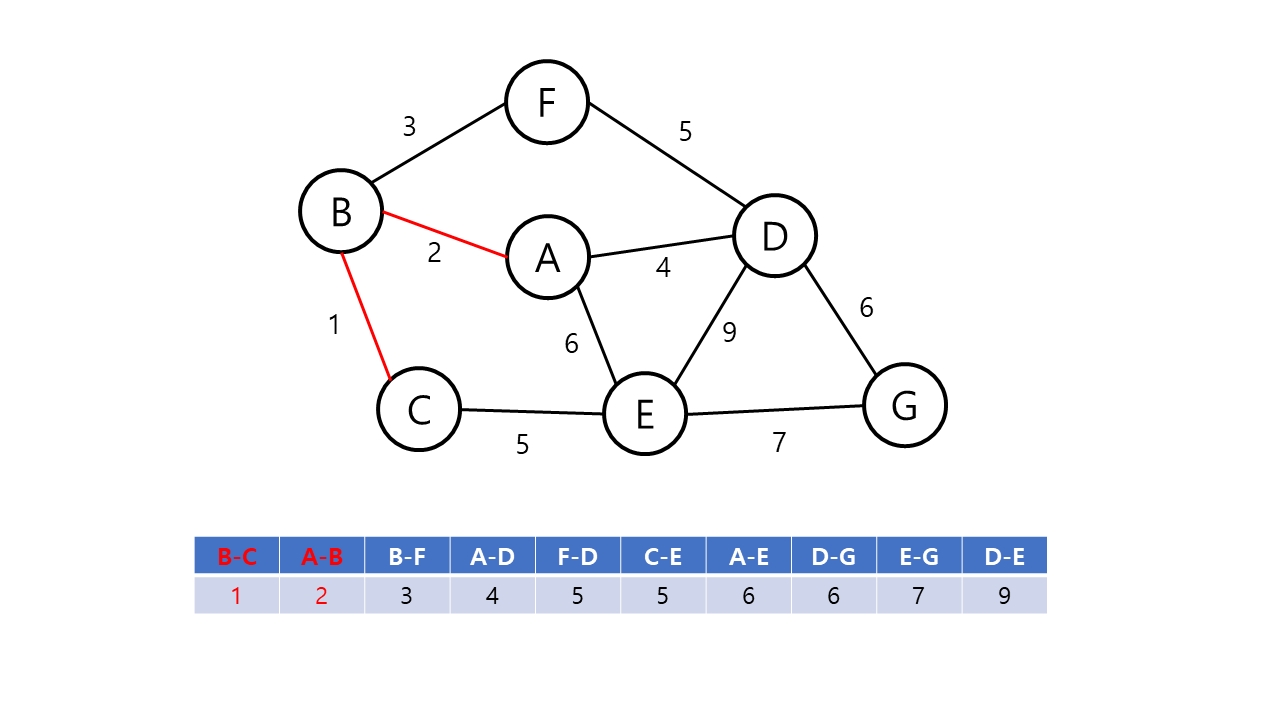
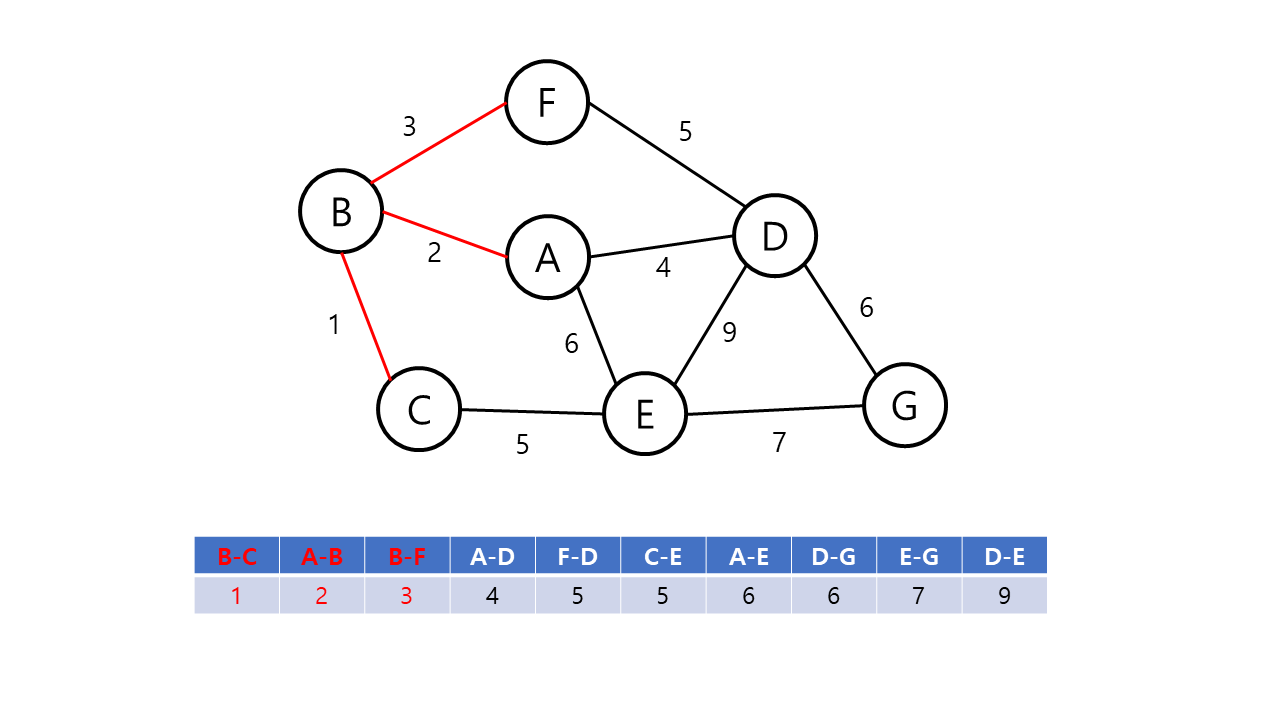
Kruskal의 알고리즘의 동작 방식은 다음과 같다.
- 그래프의 간선들을 가중치의 오름차순으로 정렬한다.
- 정렬된 간선 리스트에서 사이클을 형성하지 않는 간선을 선택한다.
- 해당 간선을 최소 비용 신장 트리의 집합에 포함한다.
- 위의 과정을 n-1 번 반복한다.
Kruskal의 알고리즘은 다음 간선을 이미 선택된 간선들의 집합에 포함하기 전에 사이클을 형성하는지 확인해야 한다. 이 때 같은 집합에 속해 있는 정점 간의 간선을 추가할 경우 사이클이 형성된다는 점에 근거하여, Union-Find 알고리즘을 사용해 사이클의 형성을 확인한다.
구현
C에서 Kruskal의 알고리즘은 다음과 같이 구현된다.
typedef struct{
int key;
int u;
int v;
}element;
void kruskal(int n)
{
int edge_accepted=0; // 현재까지 선택된 간선의 수
HeapType h; // 최소 힙
int uset, vset; // 정점 u와 정점 v의 집합 번호
element e; // 힙 요소
init(&h); // 힙 초기화
insert_all_edges(&h); // 힙에 간섭들을 삽입
set_init(n); // 집합 초기화
while(edge_accepted < (n-1)){ // 간선의 수 < n-1
e = delete_min_heap(&h); // 최소 힙에서 삭제
uset = set_find(e.u); // 정점 u의 집합 번호
vest = set_find(e.v); // 정점 v의 집합 번호
if(uset != vset){ // 서로 속한 집합이 다르면
printf("(%d, %d) %d \n", e.u, e.v, e.key);
edge_accepted++;
set_union(uset, vset); // 두개의 집합을 합친다.
}
}
}
시간 복잡도
union-find 알고리즘을 이용하면 Kruskal의 알고리즘의 시간 복잡도는 간선들을 정렬하는 시간에 좌우된다. 따라서 간선 E개를 퀵 정렬과 같은 효율적인 알고리즘으로 정렬한다면 Kruskal 알고리즘의 시간 복잡도는 O(Elog E)이 된다.
Prim의 MST 알고리즘
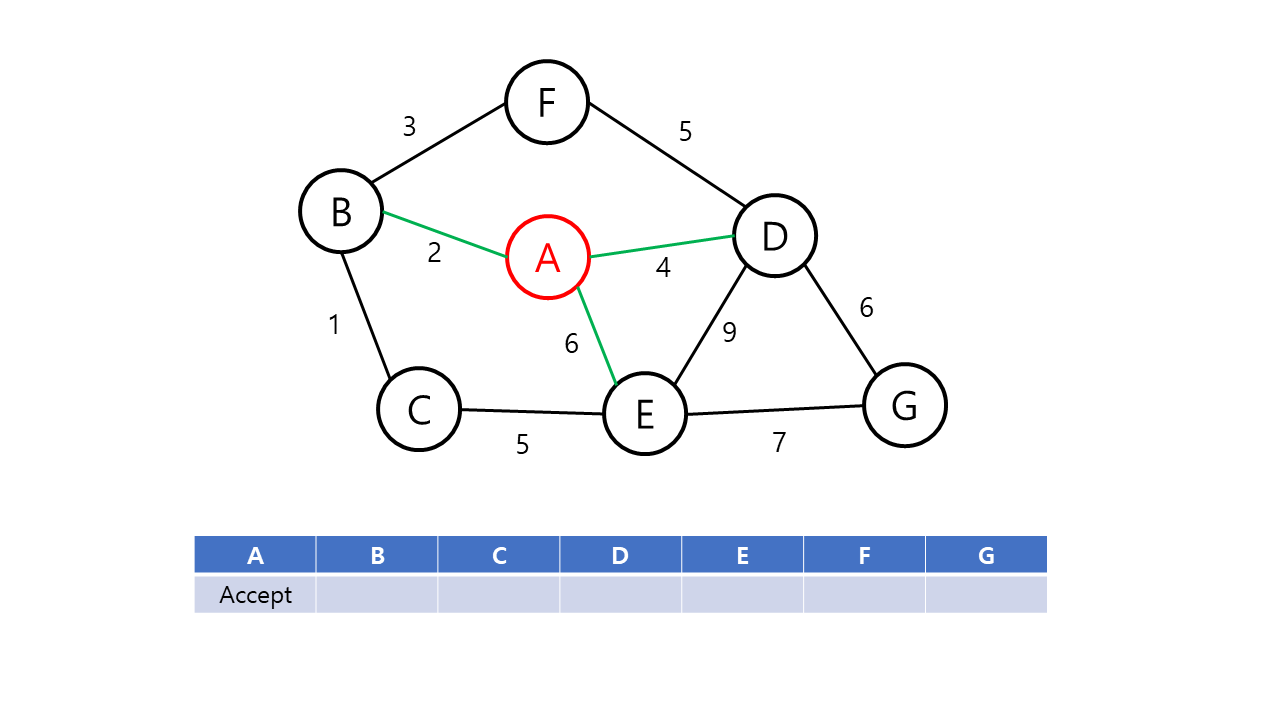
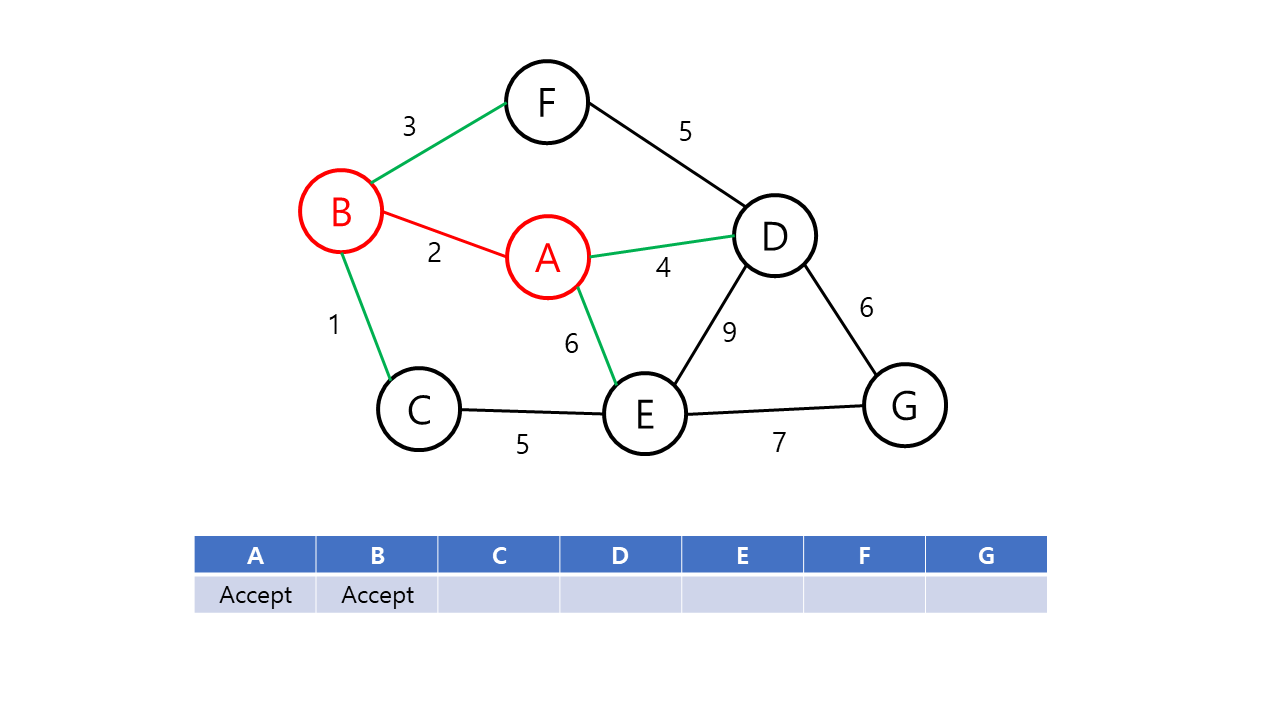
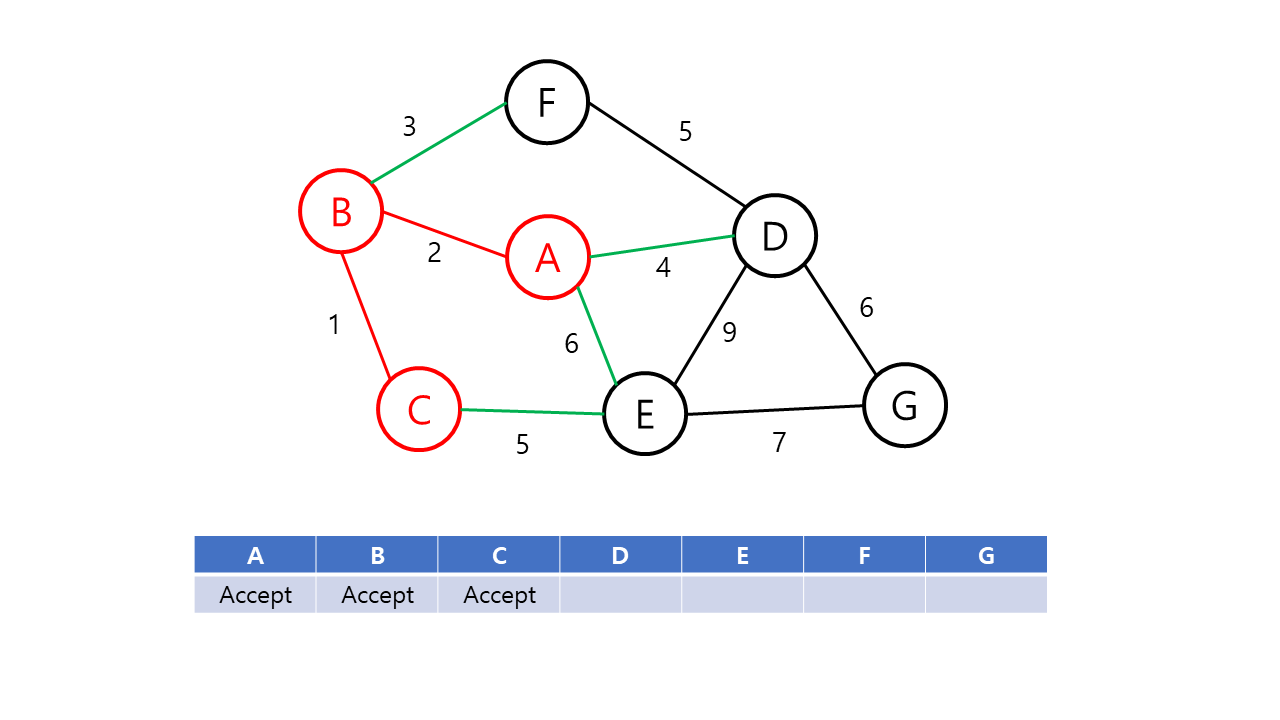
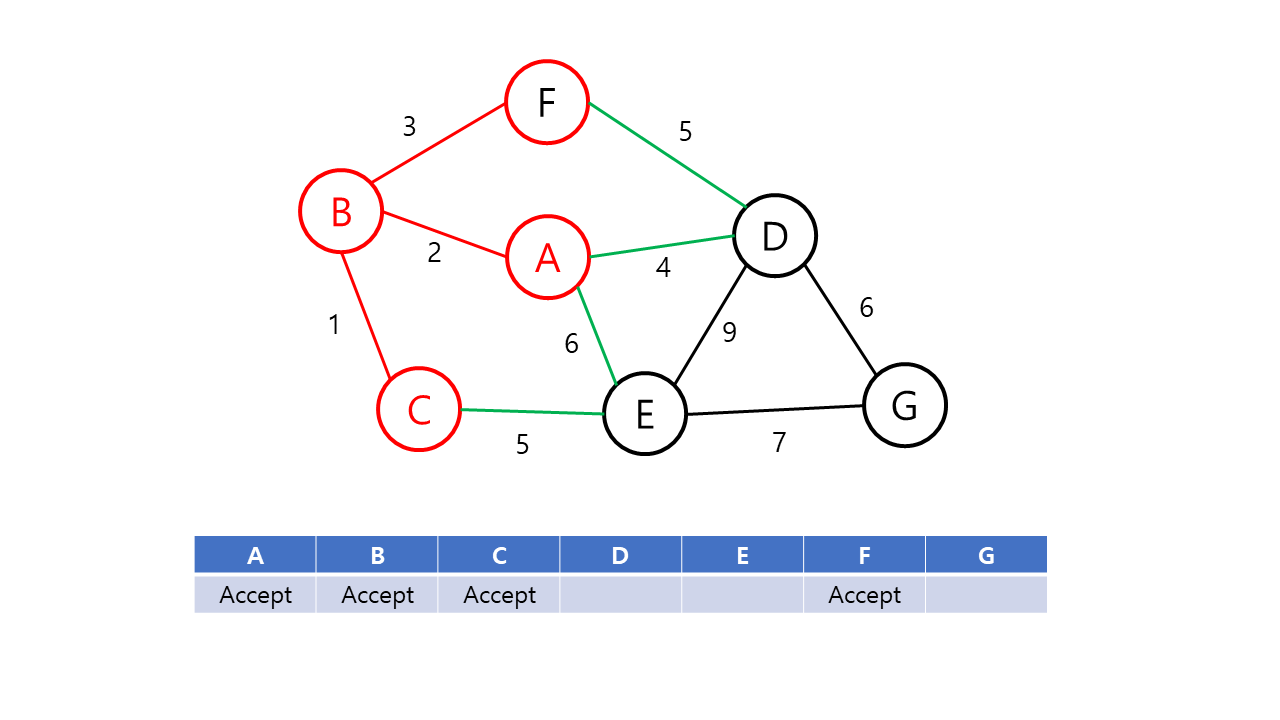
Prim의 알고리즘은 시작 정점에서부터 출발하여 신장 트리 집합을 단계적으로 확장해나가는 방법이다.
동작 방식
Prim의 알고리즘의 동작 과정은 다음과 같다.
- 시작 단계에서 시작 정점만이 신장 트리 집합에 포함된다.
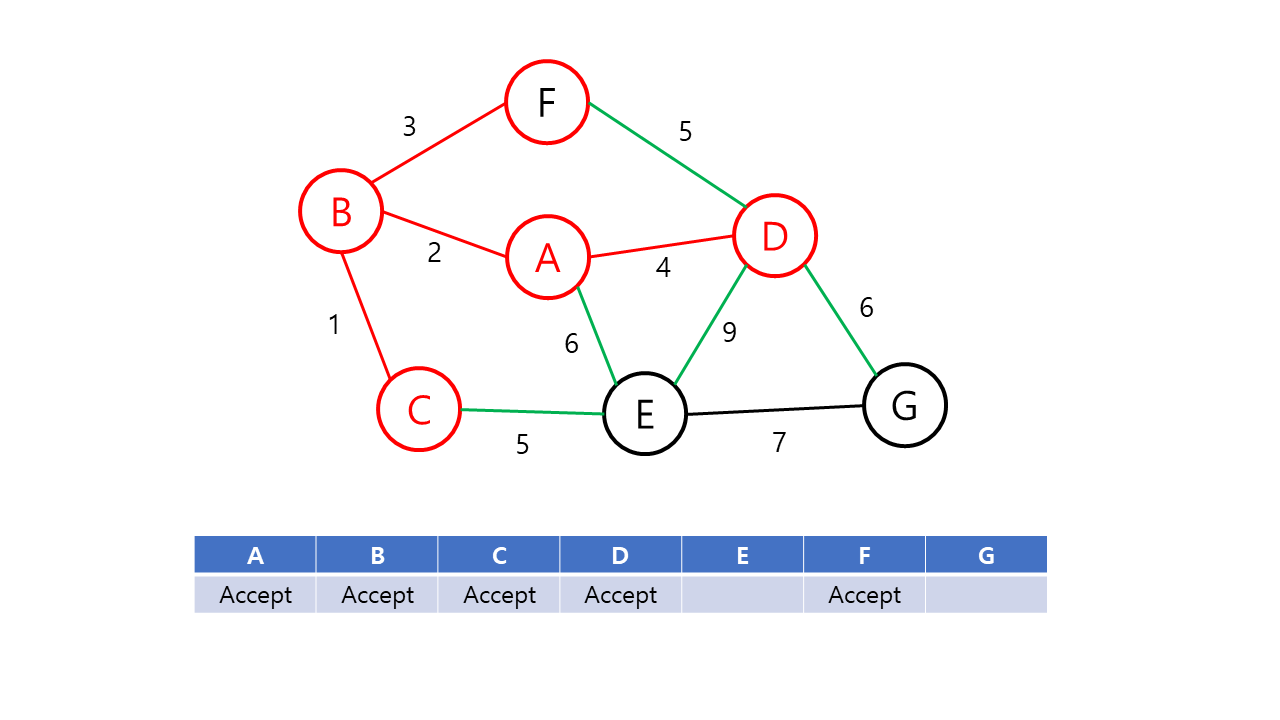
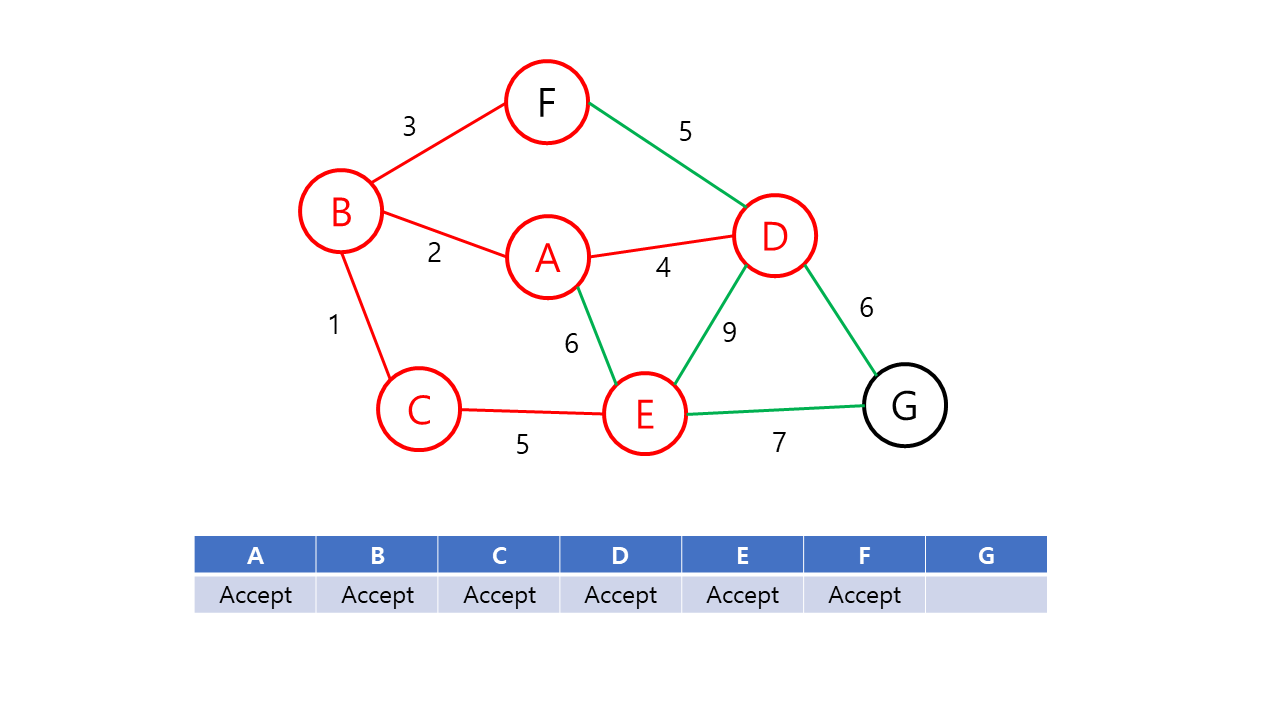
- 앞 단계에서 만들어진 신장 트리 집합에 인접한 정점들 중에서 최소 가중치 간선으로 연결된 정점을 선택하여 신장 트리 집합에 추가한다.
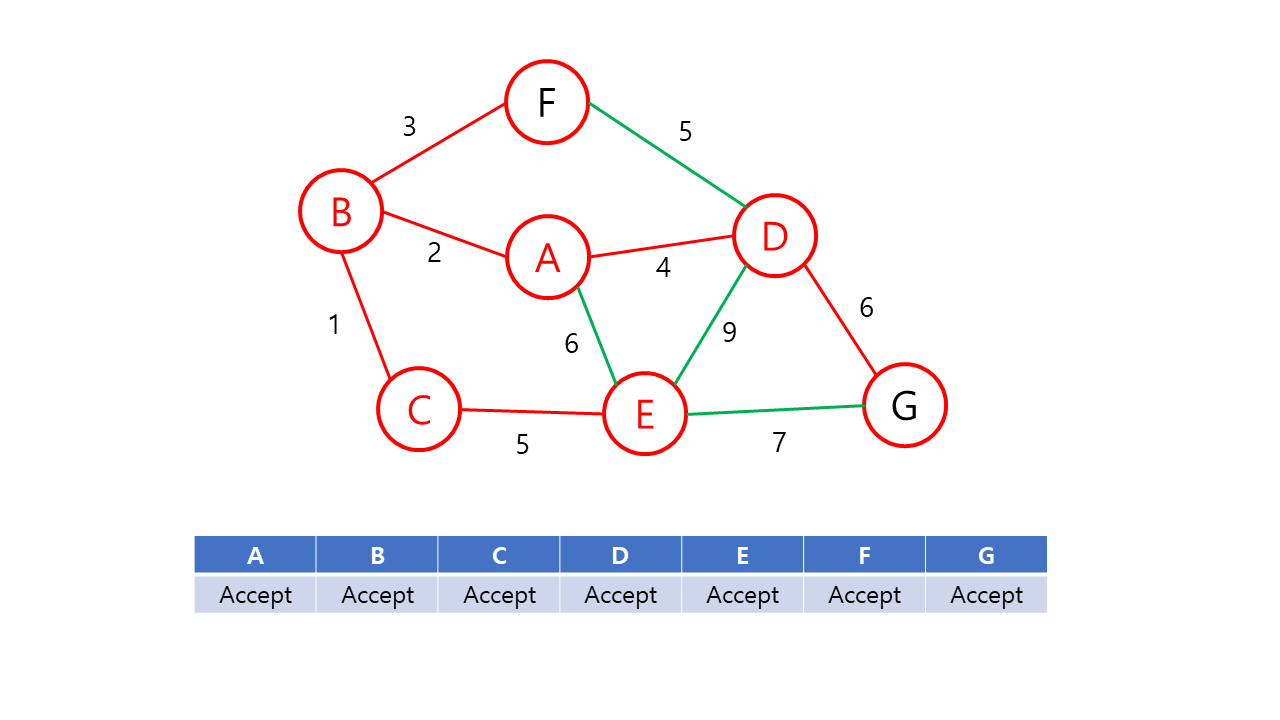
- 신장 트리 집합이 n-1개의 간선(정점 n개)를 가질 때까지 2를 반복한다.
구현
C에서 Prim의 알고리즘은 다음과 같이 구현된다.
int selected[MAX_VERTICES]; // 신장 트리 정점에 각 정점이 포함되었는지를 저장하는 배열
int dist[MAX_VERTICES] // 현재까지의 신장 트리 정점 집합에서 각 정점까지의 거리를 저장하는 배열
// 최소 dist[v] 값을 갖는 정점을 반환
int get_min_vertex(int n) // 파라메터 : 모든 정점의 수
{
int v, i, mindist = INF;
for(i = 0; i < n; i++){
if(!selected[i] && dist[i] < INF){ // 방문하지 않았으면서 신장트리집합으로부터 가장 적은 가중치를 갇는 정점
mindist = dist[v];
v = i
}
}
return v;
}
void prim(int s, int n) // 파라메터 : 시작정점, 모든 정점의 수
{
int i, u, v;
for(u = 0; u < n; u++){ // 신장트리집합 초기화, 신장트리집합에 속한 정점이 없으므로
dist[u] = INF;
selected[u] = FALSE;
}
dist[s] = 0; // 시작정점의 거리를 0으로 설정. 아직 집합에 추가하지 않음
for(i = 0; i < n; i++){
u = get_min_vertex(n);
selected[u] = TRUE; // 정점 u를 신장트리집합에 추가
if(dist[u] == INF) return; // 신장트리와 정점 u 사이에 간선이 없으면 종료. 신장트리를 만들 수 없는 경우.
printf("%d ", u);
for(v = 0; v < n; v++){
if(weigth[u][v] != INF){ // 이번 반복문에서 선택된 정점 u와 임의의 정점 v간의 간선이 존재하는 경우
if(!selected[v] && weight[u][v] < dist[v]) // 정점 v가 선택되지 않고 정점 v와 기존 신장트리와의 거리보다 정점 u와의 거리가 더 짧을 경우
dist[v] = weight[u][v]; // 가중치 갱신
}
}
}
}
시간 복잡도
Prim의 알고리즘은 선택 가능한 간선 중 최소 가중치의 간선을 선택하는 작업을 총 정점의 수만큼 반복한다. 따라서 최소 가중치의 간선을 선택하는 방법을 힙 정렬과 같은 O(nlogn)의 방법으로 선택할 경우 O(ElogV)의 시간 복잡도를 갖는다.
Kruskal과 Prim의 비교
Kruskal의 시간 복잡도가 O(ElogE)인 반면에 Prim의 시간 복잡도는 O(ElogV)이다. 따라서 그래프 내의 간선이 적은 희소 그래프의 경우 Kruskal이, 밀집한 그래프일 경우 Prim이 유리하다고 볼 수 있다.
참조
천인국,공용해,하상호. 『C언어로 쉽게 풀어쓴 자료구조』. 생능출판, 2017.