다익스트라(Dijkstra) 알고리즘
Dijkstra의 최단 경로 알고리즘
Dijkstar의 최단 경로 알고리즘은 네트워크에서 하나의 시작 정점으로부터 모든 다른 정점까지의 최단 경로를 찾는 알고리즘이다.
간선에 대한 정보를 인접 행렬을 통해 저장한다고 가정하자. 정점 간의 가중치는 가중치 인접 행렬이라고 불리는 2차원 배열에 저장된다. 이 때, 인접 행렬에서는 간선이 없으면 인접 행렬의 값이 0 이었다. 하지만, 가중치 인접 행렬의 경우 간선의 가중치가 0일수도 있기 때문에 0의 값이 간선이 없음을 의미하지 못한다. 따라서, 가중치 인접 행렬에서는 무한대의 값(INF)을 이용하여 정점 간에 간선이 없음을 표현한다.
동작 방식
Dijkstra의 알고리즘은 다음과 같이 동작한다.
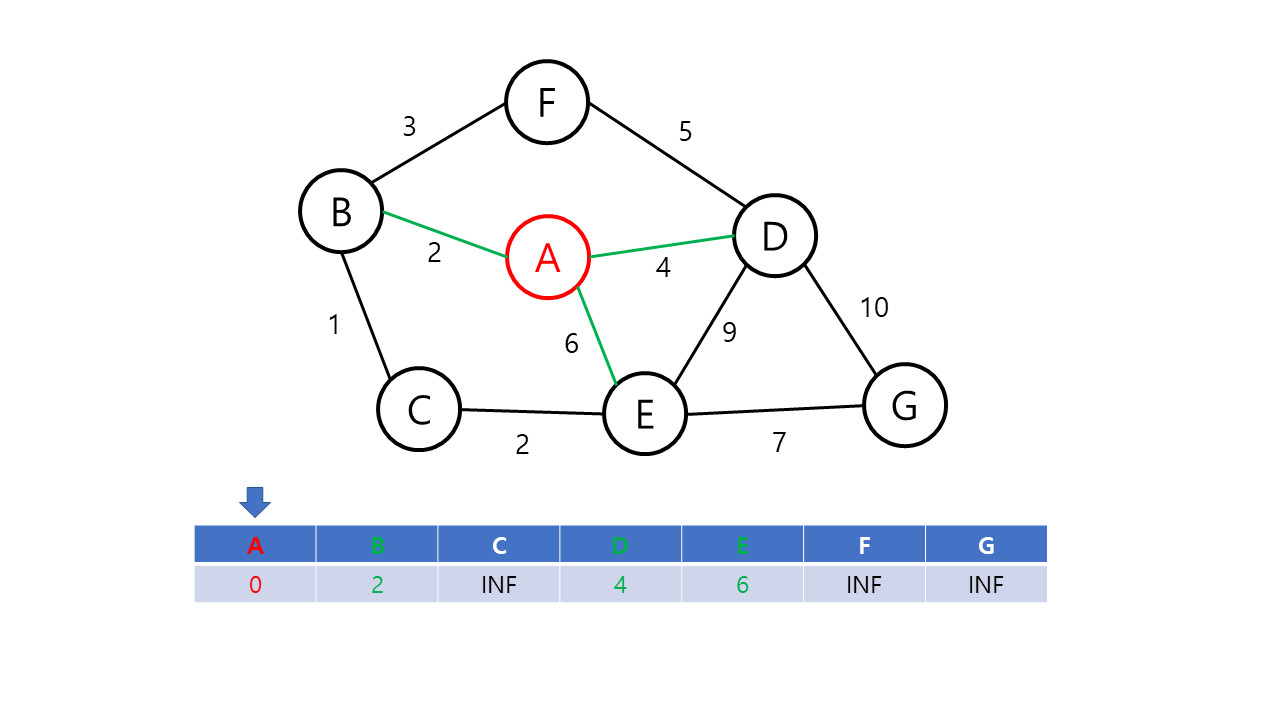
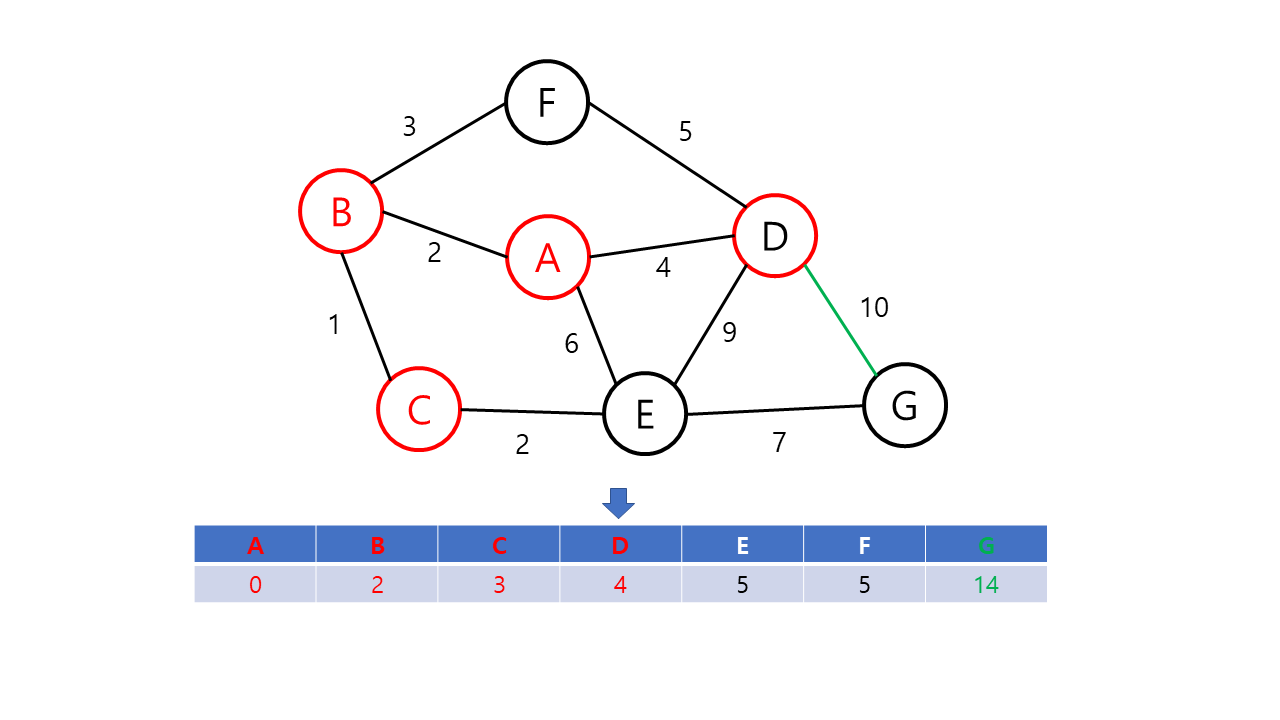
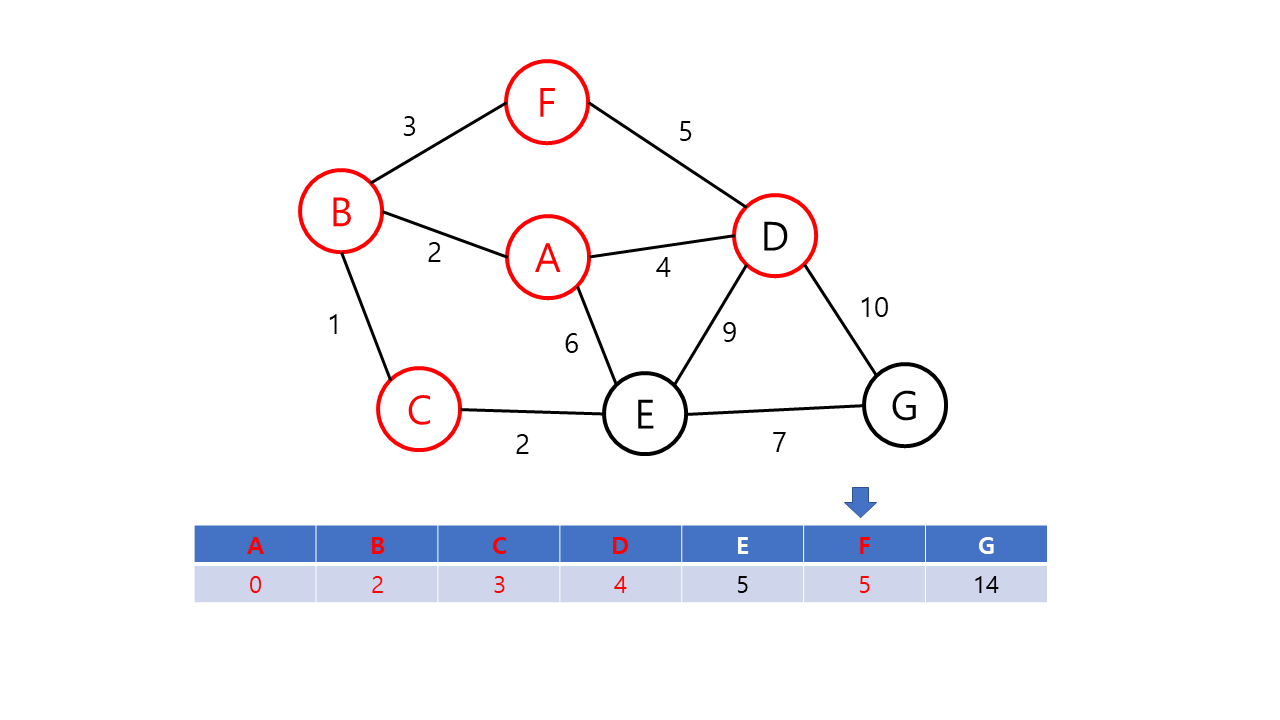
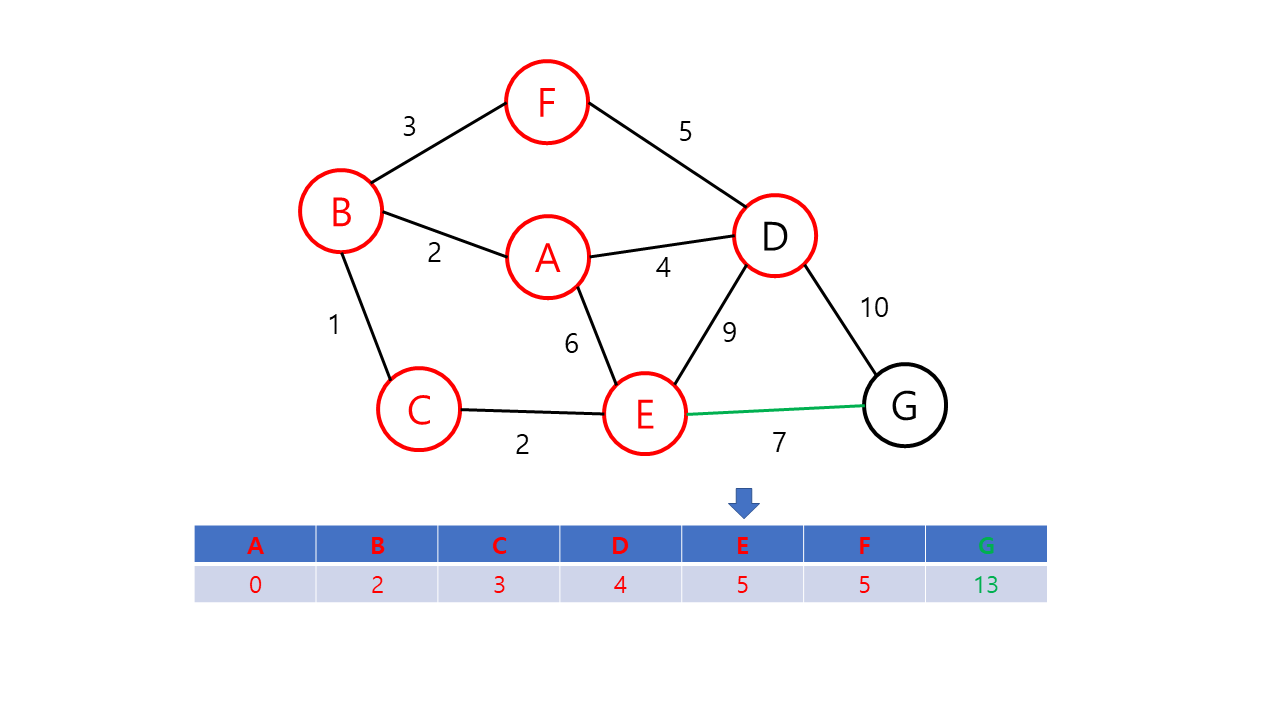
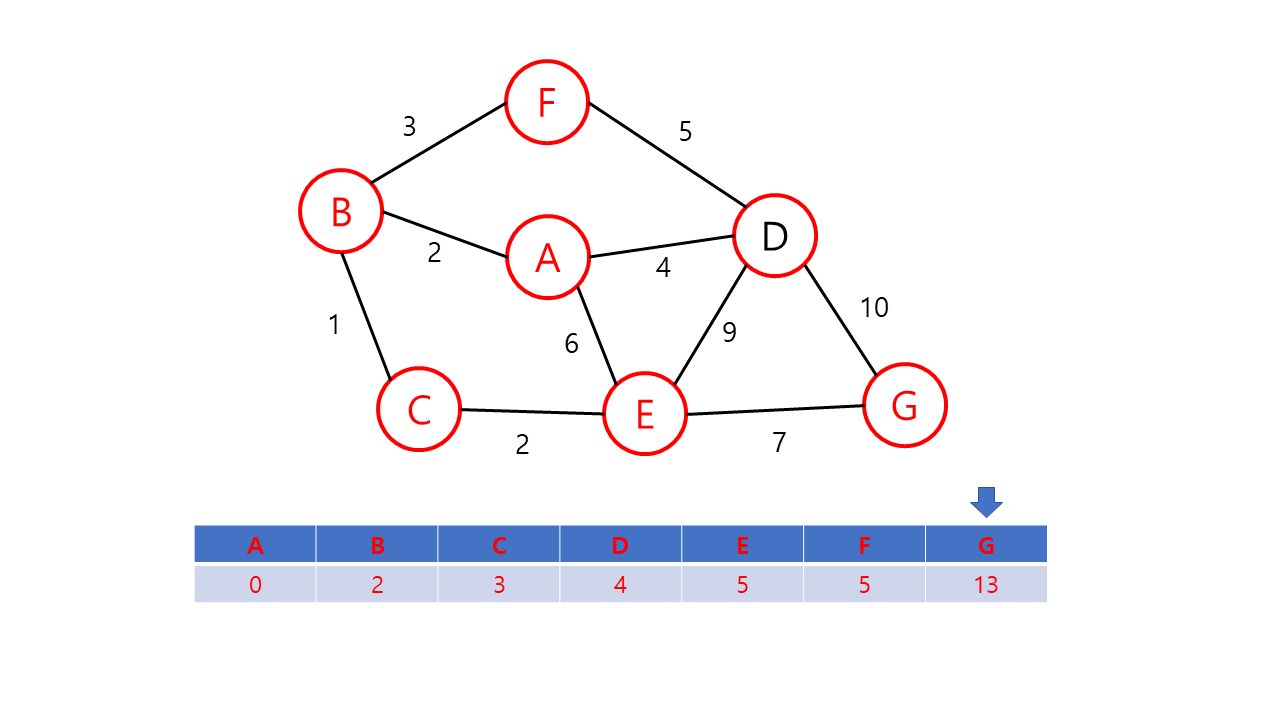
- 출발점으로부터 각 정점에 대한 최단 거리를 저장할 배열 dist[v]를 만들고, 출발 노드에는 0을 다른 노드에는 무한대(INF)의 가중치를 저장한다. (아직 출발 노드를 방문하지 않은 상황이다.)
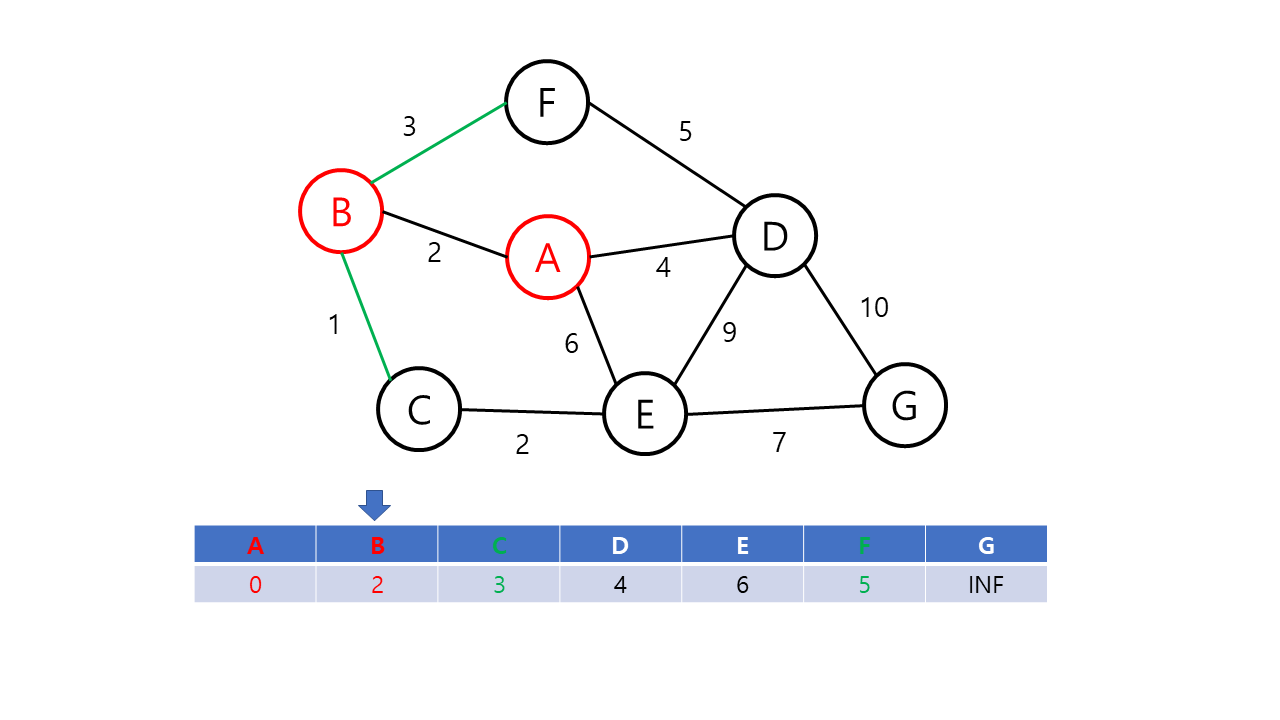
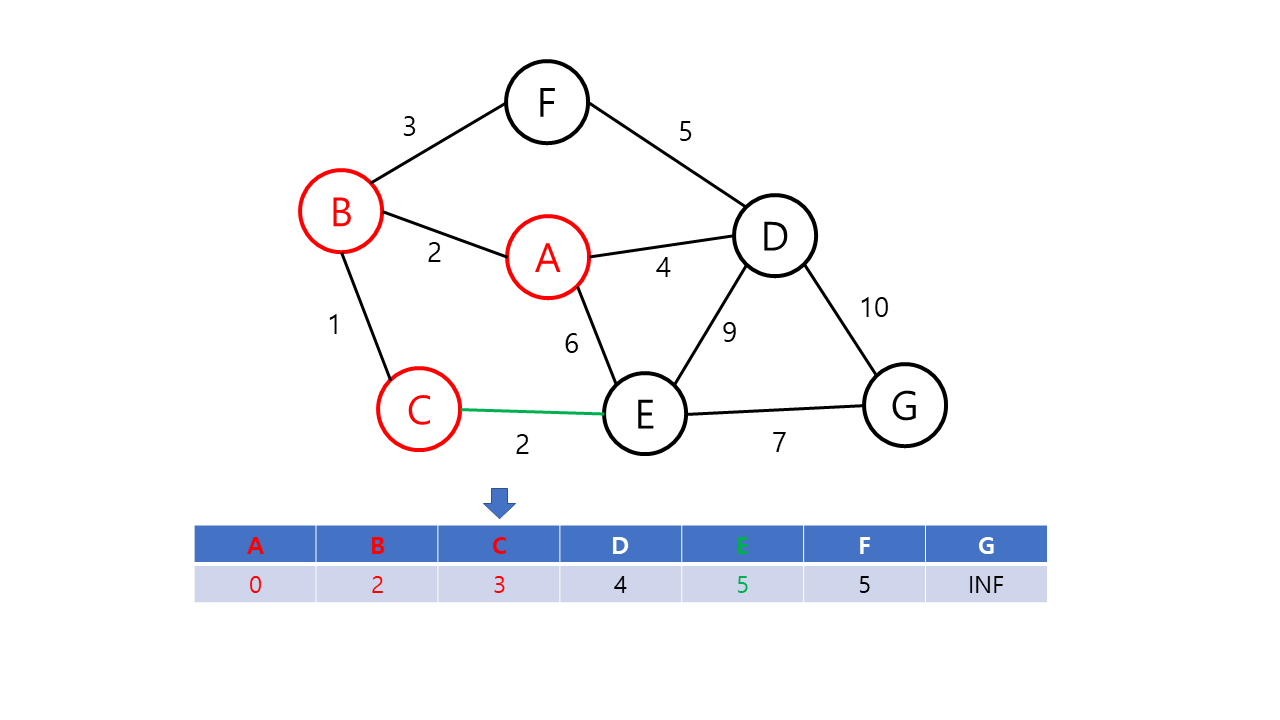
- 루프문을 돌려 방문 노드(초기값은 출발 노드)와 이웃한 노드들간의 거리를 dist[v]에 저장한다. 이 때, 이번 루프에서 얻은 가중치가 기존의 가중치보다 적을 경우 dist[v] 값을 교체한다. 예를 들면 방문 순서가 A-B-C이고 기존 dist 값인 w[a][c]보다 w[a][b] + w[b][c]가 더 작을 경우 dist 값을 교체한다. 이후 출발 노드에 방문 표시를 한다.
- 미방문한 노드들 중에서 dist[v] 값이 가장 적은 노드를 선택하여 다음 방문 노드로 설정한다.
- 모든 노드가 방문 완료 상태가 되거나 미방문 상태의 노드를 방문할 수 없을 때가지 2~3를 반복한다. 작업 이후 dist[도착노드]에 저장된 값이 출발 노드와 도착 노드까지의 최단 거리이다. 만약, 이 값이 INF라면 출발 노드와 도착 노드 간의 길이 없음을 의미한다.
구현
C에서 Dijkstra의 알고리즘은 다음과 같이 구현된다.
#define MAX_VERTICES // 최대 정점 수
#define INF // 최대 정수
#define INF_DIST // 무한대(연결이 없는 경우)
int weight[MAX_VERTICES][MAX_VERTICES]; // 가중치 배열
int distance[MAX_VERTICES]; // 시작 정점으로부터의 최단 경로 거리
int found[MAX_VERTICES]; // 방문한 정점 표시
int choose(int distance[], int n, int found[])
{
int i, min, minpos;
min = INF_DIST;
minpos = -1;
for(i = 0; i < n; i++){
if(distance[i] < min && !found[i]){
min = distance[i];
minpos = i;
}
}
return minpos;
}
void dijkstra(int start, int n)
{
int i, u, w;
for(i = 0; i < n; i++){ // 초기화 (+ 시작 정점 방문)
distance[i] = weight[start][i];
found[i] = FALSE;
}
found[start] = TRUE; // 시작 정점 방문 표시
distance[start] = 0;
for(i = 0; i < n-1; i++){
u = choose(distance, n, found);
found[u] = TRUE;
for(w = 0; w < n; w++){
if(!found[w]){
if(distance[u]+weight[u][w] < distance[w])
distance[w] = distance[u]+weight[u][w];
}
}
}
}
시간 복잡도
네트워크에 n개의 정점이 있다면 Dijkstra 최단 경로 알고리즘은 주 반복문을 n번 반복하고 내부 반복문을 2n번 반복하므로 O(n^2)의 시간 복잡도를 가진다.
효율성을 높이기 위해서는 최소 거리인 정점을 선택하는 과정을 우선순위 큐로 대치하면 더 빠르게 수행시킬 수 있다. 이는 두 과정을 통해서 이루어지는데 첫 번째로는 각 정점마다 인접한 간선들을 모두 탐색한다. 모든 간선들이 한 번씩 탐색되므로 O(E)의 시간복잡도를 갖는다. 그 다음 그 간선에 연결된 정점까지의 거리를 우선순위 큐에 삽입하는 과정으로 각 정점이 우선순위큐에 삽입될 때마다 시간 O(E)의 시간 복잡도를 갖는다. 이를 합치면 O(ElogE)의 시간 복잡도를 갖는다.
일반적인 그래프의 경우, E < V^2 이므로 logE < logV^2이다. 따라서 하나의 간선에 대해 시간 복잡도 O(logE) < O(logV)라고 볼 수 있으며 다익스트라의 시간 복잡도는 O(ElogV)로 표현될 수 있다.
참조
천인국,공용해,하상호. 『C언어로 쉽게 풀어쓴 자료구조』. 생능출판, 2017.
이형원. 『차근차근 이해하는 알고리즘』. 정익사, 2015.